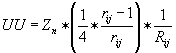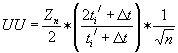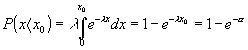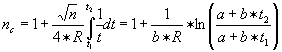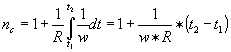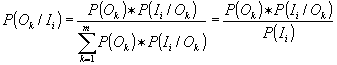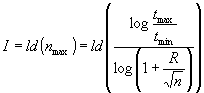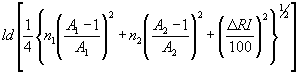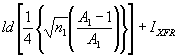![]()
1
MULTIDIMENSIONAL CHROMATOGRAPHY
Jiří G.K. Ševčík
, Dept. Anal. Chemistry, Charles University Prague© Jiří G.K. Ševčík, 2002
Lecture
Part 1 –
UNCERTAINTYThe main task of all separation methods is to separate mixtures of analytes to the individual components.
The random process of a separation of an unknown mixture is characterized by its ultimate uncertainty UU. For one-dimensional system it holds that
|
|
1 |
Eq. 1 comprises two terms, the number of analytes Zn , and the efficiency of the separation system. By solving the equation for separation efficiency we obtain
|
|
2 |
|
|
3 |
where Zn is a number of analytes, rij is relative retention for analytes i to j, and Rij is their resolution.
Because it holds that
|
|
4 |
|
and |
|
|
|
5 |
the equation for the ultimate uncertainty can be rewritten in the form
|
|
6 |
From Eq. 6 it can be seen that expression in parentheses equals two for
Δt = 0 and approaches unity for Δt >> ti‘ . Therefore, the ultimate uncertainty is determined by the separation system efficiency.For number of analytes Zn separated from an unknown mixture it can be assume that the analytes will be randomly distributed along the separation axis defined in terms of the retention time, retention volume, retention index, etc. Thus the probability of the retention position x is expressed by the normalized function
|
P(x) = l * e–lx |
7 |
where
λ is the component mean density on the separation axis.The probability that two peaks differ by a minimal distance x0 is given by Eq. 8. It holds that
|
|
8 |
while e
-α¨ is the probability of peak overlaping.The value of α is called saturation factor which expresses a saturation of separation space
X defined in terms of retention characteristic interval, for exmple <t1,t2>, that is the mean number of peaks within a minimual distance x0. It holds that|
|
9 |
where nc is called the peak capacity (the maximum number of separated peaks within distance x0 ) and can be expressed for different chromatographic modes. For the isothermal mode holds that
|
|
10 |
where R is the resolution required and the peak width is expressed as (a+btx ).
For a linear temperature program mode (assuming a constant peak width) it holds that
|
|
11 |
When comparing Eqs. 10 and 11 it can be seen that the temperature program mode is superior to the isothermal mode and decreases the ultimate uncertainty of measurements. Fig. 1 shows the effect of the efficiency only (a factor 3.9 ) while the effect of polarity (due to the temperature change of the stationary phase) is not included.
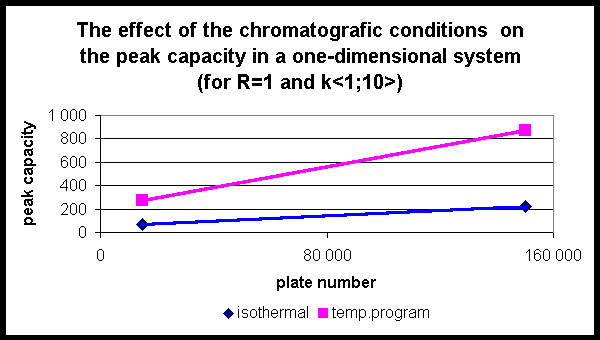
Various number of components, n, can be found within separation distance x0 . For the probability of overlapping n components holds that
|
|
12 |
The total number of overlapping clusters with the same number of peaks is
|
|
13 |
where the total number of peaks presented in the separation space X is given by the sum of pn . It holds that
|
|
14 |
Figure 2 shows the number of singlets in one-dimensional mode as the function of the number of plates for m =100 and k <1;10> .
Part 2 –
MULTIDIMENSIONALITY
What is the chromatographic dimension?
It is necessary to differentiate between multidimensional chromatopgraphic systems and multidimensional switching systems.
A chromatographic dimension is characterized by a constant value of the distribution constant of an analyte within its analysis. Thus experimental arrangements leading to its change within one run (such as different stationary phases, different temperatures) belong to multidimensional chromatography systems.
A switching dimension is characterized by a straight “sample inlet-separation part-detector” within one analysis run.An experimental arrangement leading to multiplication of any part of the trajectory belongs to multi-dimensional switching systems.
It is evident that there can exist multidimensional chromatography without mulditimensional switchning (temperature program modes) and multidimensional switching without multidimensional chromatography (pre- or post-column splitting).
Hyphenated techniques can be both multidimensional separation systems (HPLC-GC) and multidimesional switching systems (FID-MS). Interfaces of different techniques (GC-FTIR) are very often considered as hyphenation labeled but are not necessarily multidimensional.
In multidimensional chromatography, the distribution constant is diferent in each part, and thus the analytes will behave different by them. Therefore, the separation in a one-dimensional system will be enhanced in proportion to the number of chromatographic dimensiones d. Thus an equivalent of Eq. 13 holds for d-dimensional space
|
|
15 |
|
The equivalent of Eq. 14 is |
|
|
|
16 |
Equation 16 demonstrates the improvement attained by a multidimensional separation. The peak capacity increases with the number of dimensiones and in an ideal case (non intercorrelated dimensions) it corresponds to the product of the single dimension capacities. It holds that
|
|
17 |
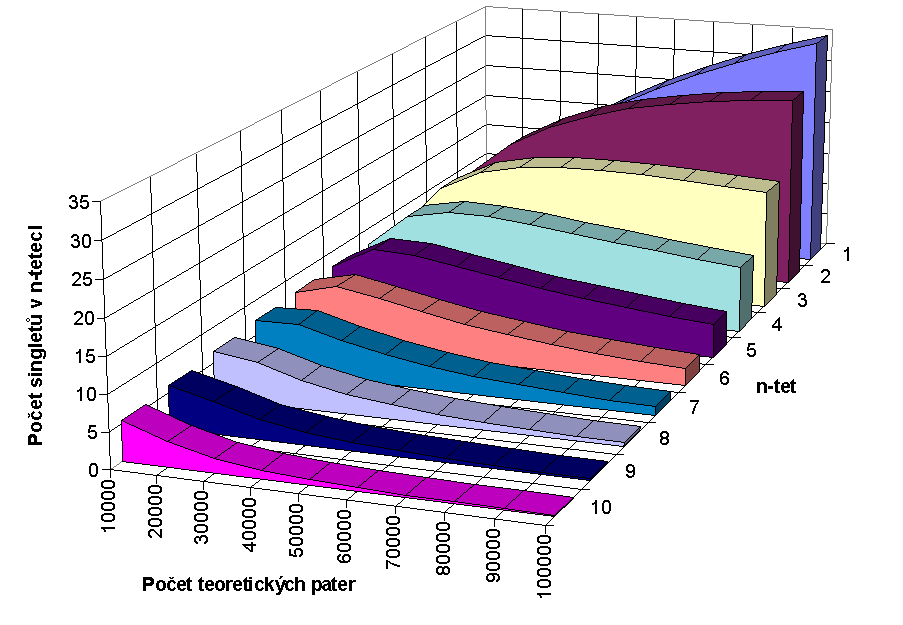
The dependence of a relative number of peaks (p/¯m) on a total number of components (¯m) for 1 to 4 dimensional chromatographic systems is shown in Fig. 3 (for k<0;10> and R=1). Under ideal conditions, the number of components increases 31 times with each dimension or the probability of identification improves 31 times for the same number of components.
It has been shown that an added dimension reduces ultimate uncertainty. What are the criteria for an additional dimension?
Part 3 –
INFORMATION CONTENT
The most general crirerion for applicability of a new dimension is evaluation of the information content. The information theory is based on evaluation of the uncertainty (entropy) prior to an experiment and after it. The uncertainty is thus related to probability that some input and output events will happen. As the input we can use the analyte identity for i = 1 to n, expressed as P(Ii), while an output corresponds to the probability that there will be a measurable signal (larger than LOD) P(Ok). The output-input relation is probability P(Ok/Ii) which corresponds to the probability that the signal Ok will be measured only when there will be input Ii and can be expressed by Bayes equation (conditional probability). It holds that
|
|
18 |
Probability P(Ii/Ok) espresses situation that there will be input Ii (component i will be present) when there will be measured output Ok . The relation of all the probabilities is shown in Fig. 4 and it holds for all of them that they are positive, normalized and additive.
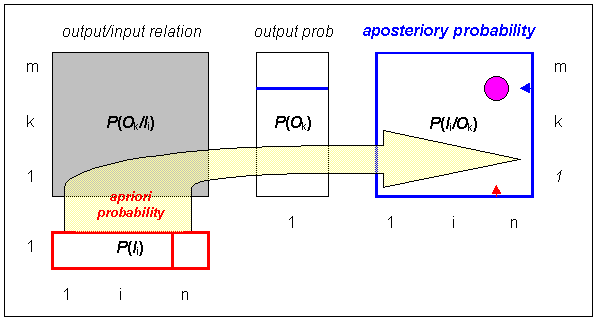
For entropy (“uncertainty”) of the above mentioned statuses it holds according to Shannon that:
|
for a priori status |
|
|
|
19 |
|
for a posteriori status of measured output Ok |
|
|
|
20 |
|
while for a posteriory status of the analysis performed |
|
|
|
21 |
Information (in terms of the information content) is defined as the diference between the uncertainties before and after analysis and it holds that
|
|
22 |
When using a multidimensional system we have the same a priori uncertainty H(I) but because of the additivity of probabilities, the a posteriory probability and the information content of multidimesional analysis I(I/
O) will increase. It holds that|
|
23 |
where I(d) expresses intercorrelated informations.
To express the information content of multidimensional systems according to Eq. 23, following approches are used:
Approaches based on the peak capacity are best suited for espression of the information content of multidimensional systems then they reflect both the separation system properties (efficiency, selectivity, switching, etc.) and the sample behaviour (peak overlapping). For information content holds that
|
|
24 |
Details on the information content calculation are beyond the scope of this lecture. As an example, the expressions and values for a multidimensional system with columns in series are given in Table 1.
|
multidimensional mode |
expression of information content |
[bit] |
|
I XFR = |
|
3 to 8 |
|
I MON = |
|
5 to 11 |
Part 4 -
MULTIDIMENSIONAL HW
Validity of Eq. 23 constitutes the background for purposeful and substantiated development of analytical instrumentation. It comprises every step of analysis which leads to an improvement in an a posteriori probability, different injection techniques, stationary phases, columns and their combinations, detectors, etc.
Generally there are three approaches for development of a new sophisticated instrumentation:
|
|
25 |
|
|
26 |
|
|
27 |
Multidimensional separation hardware systems are serial, parallel or combined. In a serial system, the sample separation is carried out first under given conditions characterized by distribution constant value Kd1 and then under changed conditions represented by a changed distribution constant Kd2 (Kd1 ≠ Kd2 ). This general condition of multidimensional separation holds for parallel systems as well but the sample is split into different columns and analysed simultaneously. Schematics of the two separation systems are given in Fig. 5.
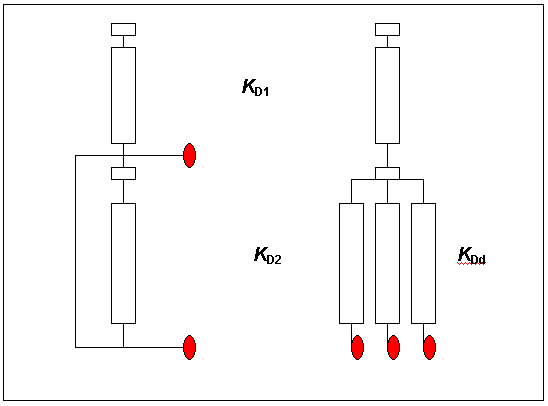
There are numerous column combinations and switching modes applied in multidimensional chromatography. Switching modes are very often used to improve efficiency of the analysis in terms of information flow and information efficiency (derived from the information content). In Table 2 are listed most frequently used modes in the multidimensional chromatography.
|
SFL |
Solvent flush |
|
XFR |
Transfer |
|
MON |
Monitoring |
|
BFL |
Back-flush |
|
TRP |
Trapping |
|
RJN |
Re-injection |
As shown above, much greater data volumes are produced in multidimensional chromatography compared to one-dimensional chromatography. Hence the working with multidimensional separation system data handling systems is more complex, and very often linked to a chain
It is evident that both hardware (mainly miniaturization) and software (mainly deconvolution routines and methods of multidimensional statistics) components are of essential importance for multidimensional chromatography development.
Multidimensional chromatography is the analytical approach to the Bohr principle of complementarity.