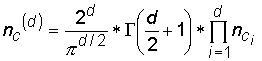
Porovnání sensorových arrays a multidimensionální chromatografie
Jiří G.K. Ševčík
Katedra analytické chemie, PřF UK, Albertov 2030, CZ-128 40 Praha 2
sevcik@natur.cuni.cz
Přednáška se věnuje porovnání dvou, zásadně se odlišujícím přístupům řešení analýzy komplexních směsí látek. První je založen na využívání sensorových polí (arrays), druhý na multidimensionální chromatografii. Tyto přístupy jsou založeny jak na odlišných fyzikálně chemických základech, ta
k na použití odlišných technologií při hardwarové realizaci. Význam a aktuálnost těchto přístupů je spojen s účinnou kontrolou a z ní vyplývajícími opatřeními proti identifikovaným chemickým látkám.Oba porovnávané přístupy mají společné postupy v řešení multidimensionálních signálů, zpravidla složených se současného příspěvku více analytů s neznámou hodnotou relativní molární odezvy. Řešení takovýchto signálů není v oblasti fyzikálního řešení, ale pouze v oblasti výpočetní inteligence, posouvající se od n
eurocomputing (bivalentní), přes fuzzy logic (spojité hodnoty 0 až 1), k SOM (Self-Organizing Maps). Výsledná řešení mají potom vždy pouze pravděpodobnostní charakter.Zbytková nejistota výpočetního řešení multidimensionálních signálů je spojena s vyhodnocením podmíněných pravděpodobností, které můžeme popsat takto:
Řešení pro multidimensionální chromatografii je založeno na teorii statistického modelu překryvu píků. Při tomto postupu je nejprve zvážena pravděpodobnost retenční posice ovlivněné střední hustotou analytů na separační ose. Dále je zvážena pravděpodobnost, že v s
eparačním prostoru existuje úsek, v němž se nachází hledaný analyt, zpravidla spolu s jinými analyty a vytváří tak určitý stupeň nasycení tohoto úseku. Každý úsek separačního prostoru je proto charakterizován tzv. píkovou kapacitou. Stupeň rozlišení Rij analytů nacházejících se v jednotlivých úsecích separačního prostoru je funkcí nasycenosti tohoto úseku a platí v něm pravděpodobnost překryvu určitého počtu píků. Z uvedeného vyplývá, že čím větší bude separační prostor a čím menší bude nasycenost separačního úseku, tím menší bude pravděpodobnost překryvu píků.Multidimensionální chromatografie je založena na různosti hodnoty distribuční konstanty v každé dimensi. Z toho vyplývá, že retenční chování analytů je různé v každé dimensi. V obou případech multidimensionálních chromatografií (paralelní a seriová) je dosaženo podobného výsledku, píkoví kapacita systému vzrůstá s počtem chromatografických dimensí
d, faktorem 2d. V ideálním případě neinterkorelovaných dimensí je výsledná píková kapacita součinem (!nikoli pouhým součtem!) píkových kapacit jednotlivých dimensí nci.
Tento efekt vede ve své podstatě k významnému snížení zbytkové nejistoty (1-
P) analytického postupu a zvýšení informačního obsahu řešení multidimensionální chromatografií.Pro sens
orová pole je odvození podmíněné pravděpodobnosti provedeno z diskuse modelu signálu analytu a celkové měřené odezvy. Z hlediska signálu analytu jsou proměnnými množství analytu mx a citlivost sensoru (k*a) pro analyt x. Podmíněná pravděpodobnost, že sensor určí analyt x z celkového měřeného signálu S je dána následujícím vztahem. Platí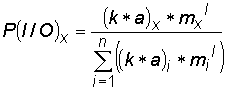
Za podmínky srovnatelné citlivosti a množství analytů tvořících vzorek je výše uvedená pravděpodobnost určena počtem analytů, 1/
n. Při řešení sensorových polí bez předseparačních stupňů má každý sensor stejný počet analytů a za uvedené podmínky srovnatelné citlivosti a množství analytů se pravděpodobnost určení analytu x nezmění s počtem sensorů.Analytická podmínka stanovení je definovaná jako desetinásobná hodnota šum
u, který v diskutovaném případě bude tvořen sumou všech ostatních signálů na odpovídajícím sensoru.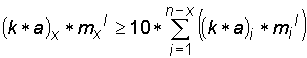
Výše uvedený vztah naznačuje podmínky hardwarového řešení sensorových polí pro analýzu organických látek v ovzduší, např. určení bojových látek, zjištění drog a výbušnin, určení aktuálního stavu požáru, apod. pomocí selektivity.
Selektivita definovaná jako poměr citlivostí dvou analytů je statisticky významná pro hodnoty ≥ 10, nižší hodnoty jsou nevýznamné. Hodnota selektivity se mění v závislosti na zvolené kombinaci analytů. Je-li významná pro analyty
xi může být nevýznamná pro xj. Požadované hodnoty citlivostí pro pro splnění podmínky meze stanovení pro čtyři analyty uvádí tabulka 1.
Tabulka 1
Příklady normalizovaných hodnot citlivostí analytů
i, n, m a x pro dosažení uvedené pravděpodobnosti určení analytu x|
příklad |
i |
n |
m |
x |
P (I/O)x |
|
a |
1 |
1 |
1 |
30 |
0,909 |
|
b |
1 |
1 |
1 |
57 |
0,950 |
|
c |
1 |
1 |
1 |
297 |
0,990 |
|
d |
1 |
10 |
20 |
3 069 |
0,990 |
Počet současně přítomných analytů v reálných vzorcích je však podstatně větší a analyty mají různé koncentrace. Nárůst požadované citlivosti pro analyt
x po změně množství ostatních analytů (příklad c a d) ukazuje nemožnost řešení sensorových polí pouze pomocí selektivity.Řešení multidimensionálních signálů sensorových polí kausálními metodami, např. multi-lineární regresí, vyžadujícími znalost kausality pro všechny přítomné analyty (a ty v aplikaci sensorových polí nejsou známy) je rovněž nemožné. Navíc vysoký stupeň interkorelovanosti mezi jednotlivými sensory pole ved
e k vysoké redundanci a následně k malému zisku informačního obsahu.Vyhodnocení informačního obsahu diskutovaných metod je vhodné pro jejich porovnání, jelikož apriorní nejistota je pro obě metody stejná. V důsledku vyšší interkorelovanosti sensorových arrays je i přes vysoký počet sensorů (dimensí), jejich zbytková nejistota vyšší než pro multidimensionální chromatografii.
![]()
Analýza výše uvedené nerovnosti je základem k novým konstrukčním řešením sensorových polí založených nikoli na zvýšení počtu dimensí, ale na snížení interkorelovanosti a zvýšení pravděpodobnosti určení analytu na dílčím sensoru.