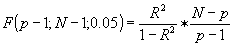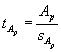![]()
(1)
Od výsledku k informaci pomocí vícerozměrné statistiky
Jiří G.K. Ševčík, Katedra analytické chemie PřF UK, Albertov 2030, Praha 2
Analytické řešení zadaného problému je komplexní, interdisciplinární úkol, tvořený několika na sebe navazujícími stupni. Tyto stupně jsou navzájem podmíněné, nikoli však více nebo méně významné. Posledním stupněm analytického řešení je vytvoření informace, tj. zvýšení stupně poznání řešeného problému.
Jelikož zadání nebývá formulováno ve smyslu zjištění analytických hodnot, či použití určitých metod, je přeformulování tohoto zadání do analytické metody nejkritičtějším článkem analytického postupu. Zatímco výsledek, jeho parametry, existuje i mimo zadání, je informace získatelná jen ve spojení se zadáním (máme-li řešit problém
úhynu ryb, poskytují tabulky logaritmů pro toto řešení nulovou informaci). Různými analytickými postupy lze získat různě přesné výsledky (shodné a opakovatelné) a z nich lze získat informace, které budou různě komplexní a jednoznačné (vyjádřeno hodnotou informačního obsahu (/(S)obt/ I(S)req) ), různě časově náročné (vyjádřeno hodnotou informačního toku (/(S)obt/tanal) a různě finančně náročné (vyjádřeno hodnotou ceny informace (/(S)obt/ $ ).Celkový analytický postup tak vytváří uzavřený kruh, začínající a končící u zadání problému (Obr. 1). Přitom je třeba zdůraznit, že analytikem navržený a realizovaný postup řešení je jedním z mnoha možných a nevede bezpodmínečně ke snížení zbytkové nejistoty řešeného problému, tj. k získání informace. V tét
o souvislosti je nesporná úloha řešitele formulujícího model řešení zadání a to hlavně ve výběru komplementárních metod s nízkým stupněm redundance.V analytické chemii jsou takžka bez výjimky používány lineární modely, jejichž vhodnost (počet proměnných
Xi, funkční vztah, atd) lze posuzovat na základě velikosti zbytkové chyby modelu ε. Linární model má obecně tvar rovnice 1. Platí|
|
(1) |
Variabilita modelů je značná a optimální řešení je zpravidla jen jedno. Vícerozměrná statistika se věnuje jak návrhům a řešení modelů, tak i vypracování posuzovacích kriterií použitých modelů. Vícerozměrná statistika však neinterpretuje obsahovou část proměnných ani jejich funkčních závislostí.
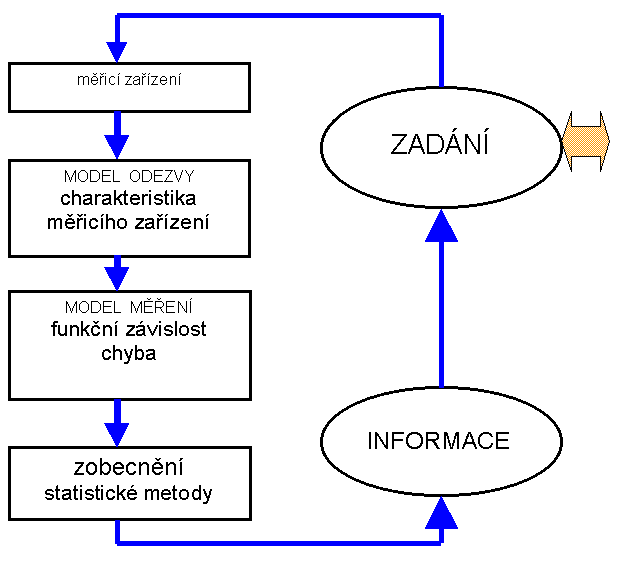
Obr. 1 Schema klíčových bodů řešení zadaného úko
luZ obr. 1 vyplývá vzájemná provázanost mezi jednotlivými stupni řešení, stejně jako odběr vzorku a jeho úprava jsou spoluzodpovědny za výsledek analýzy a ne jen samotná metoda měření. Proto například, ani sebenáročnější program nemůže vést k platnému zobecnění, jestliže při rovnovážných dějích není sledován vliv teploty.
Návrh experimentu, z hlediska určení počtu sledovaných proměnných a jejich úrovní, je klíčovým stupněm k pozdějšímu zobecnění. Obr. 2 ukazuje dva základní, avšak rozdílné přístupy při řešení zadaného problému.
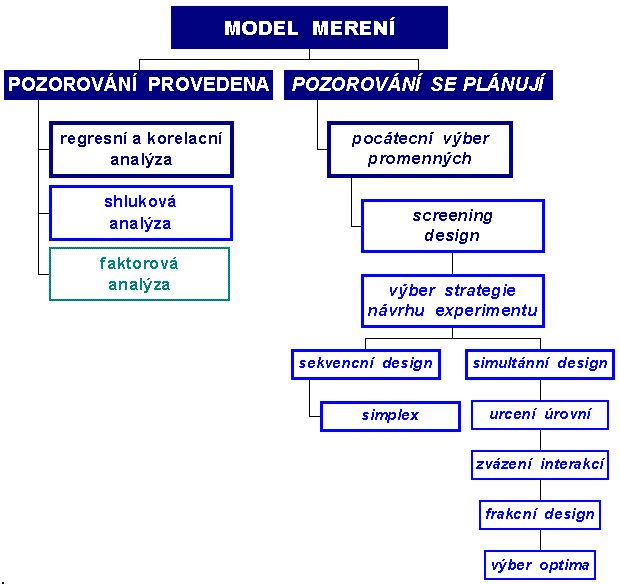
Obr. 2 Metody vícerozměrné statistiky uplatňované pro model měření
Levá strana obr. 2 představuje stav, kdy máme k disposici výsledky, získané bez jasně formulovaného zadání a nedostatky správného experimentálního uspořádání doháníme statistickými metodami. Je zřejmé, že tento přístup je nesprávný a vede k řadě nedorozumění a zcestných komentářů. Pravá strana obr. 2 naopak vede k promyšlenému měřicímu postupu, apriori se stává kriteriem ak
ceptance, či odmítnutí výsledku a ve frakčním řešení dovoluje kvantifikovat synergické efekty velkého počtu proměnných při minimálních nákladech.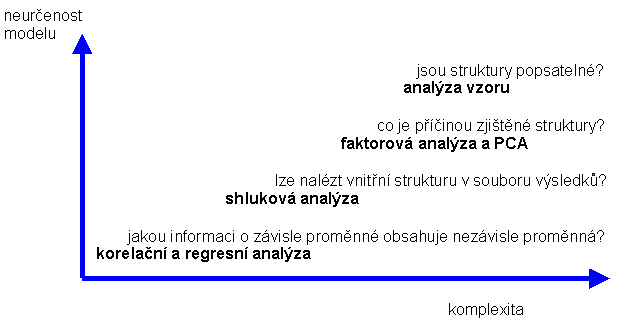
Obr. 3 Uplatnění metod vícerozměrné statistiky podle komplexnosti a určenosti modelu
Použití metod vícerozměrné statistiky není náhodné, ale má řadu pravidel a vnitřních souvislostí. Obecně, smyslem zobecňovámí je nalezení kausálního vztahu mezi pozorovanou závisle proměnnou a nezávisle proměnnými, o kterých předpokládáme, že určují velikost pozorované veličiny. Čím menší je neurčenost modelu (model je jednoznačný) a menší komplexita (počátek systému os v obr. 3), tím robustnější metody jsou aplikovány, např. korelační a regresní analýza. Se vzrůstající neurčeností modelu a jeho komplexitou se řešení pohybuj
e od kausálních metod s reálnými proměnnými k metodám se zdánlivě proměnnými. Tato logika platí i obráceně. Je-li ve výsledku řešení neuronové sítě zakódována určitá kausalita, bude možné řešení neuronové sítě převést přes faktorovou a shlukovou analýzu až k regresní analýze. Z výše uvedeného vyplývá, že použití statistických metod není otázkou dostupnosti softwarového programu, ale fundovaných úvah.V následujícím textu je ukázán postup pro řešení lipofility tří skupin látek, lišících se strukturou a předpokládaným therapeutickým účinkem. Pro dosud nesynthesované látky se předpokládalo podobné chování, jako známých derivátů. Úkolem tedy bylo zjistit kausální vztah mezi lipofilitou a strukturními vlastnostmi, který by obecně umožnil predikci l
ipofility i jen hypotetických sloučenin.Postup řešení výše uvedeného zadání je ukázán na obr. 4. Jednotlivé návazné stupně jsou upřesňovány ve formě zpětné vazby. Model vyšel ze dvou paralelních řešení, přičemž pro oba přístupy byla použita nezávisle ověřená fragmentace struktury. Model dále předpokládal, že solvatační přístup poskytne detailnější popis lipofility, ve srovnání se souhrnným popisem lipofility ve formě rozdělovacího koeficientu v systému oktanol/voda. Platí,
l, r, s, a, b, c jsou regresní koeficienty rovnice 2, zatímco logL16, R2H, π2H, α2H, β2H jsou molekulové deskriptory studovaných sloučenin.|
|
(2) |
Obr. 4 Postup při regresní analýze
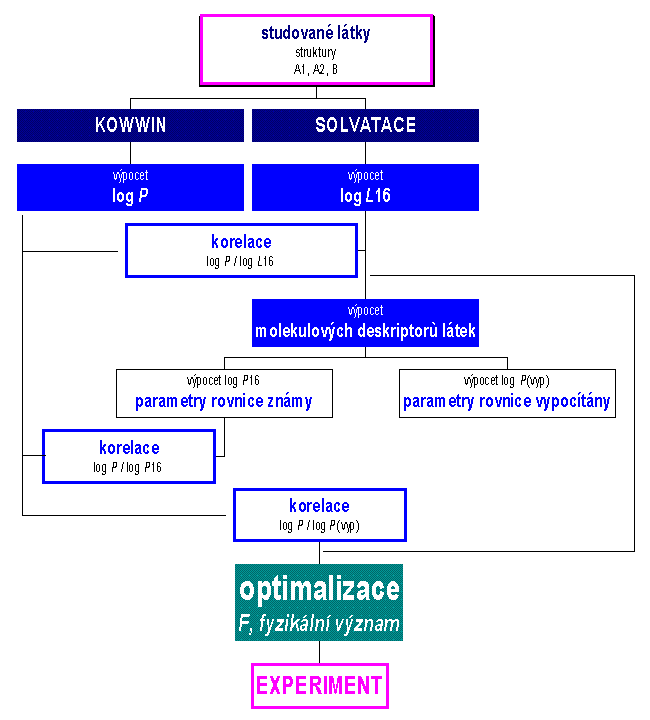
Obr. 5 Postup zobecněného výpočtu lipofility potenciálních léči
v.Poté, co byla zjištěna velmi dobrá korelovanost mezi log
P a logL16 (2. stupeň v obr. 4) bylo přistoupeno k výpočtu molekulových deskriptorů a pomocí nich byla vypočítána lipofilita pro známý soubor látek (levá část obr. 5) o známé lipofilitě. Použitá regresní analýza umožnila výpočet regresních koeficientů l, r, s, a, b, c rov. 2. Poté, co bylo ověřeno, že korelace známého souboru je vyhovující, byly parametry rov. 2 použity pro výpočet lipofility navržených látek (pravá část obr. 5). Hodnoty regresních koeficientů jsou uvedeny v tabulce 1.Tabulka 1
Hodnoty regresních koeficientů rov.2 a statistického koeficientu
F podle rovnice 3.|
F (p-1;N-1;0,05) |
regresní koeficienty rov. 2 |
|||||
|
l |
r |
s |
a |
b |
c |
|
|
v ýpočet rov. 2 ze známých hodnot lipofility |
||||||
|
153,15 |
4,453 |
0,667 |
-1,617 |
-3,587 |
-4,869 |
0,087 |
|
výpočet z menšího počtu proměnných optimovaného hodnotou F |
||||||
|
0,03 |
-1,333 |
8,528 |
||||
|
37,99 |
1,029 |
-2,995 |
1,259 |
|||
|
38,57 |
0,710 |
-1,796 |
-1,215 |
2,105 |
||
|
58,53 |
0,240 |
0,286 |
-3,039 |
-0,761 |
3,953 |
|
|
výpočet po sloučení obou souborů lá tek |
||||||
|
121 269,00 |
-0,263 |
5,911 |
-1,106 |
-2,173 |
4,393 |
|
Při výpočtu si však řešitel musí položit otázku, zdali použitý model (v našem případě rov.2) je oprávněný. Obecný postup testování modelu se skládá ze tří částí.
V první části je vhodné rozdělit studovaný soubor na dva soubory přibližně stejných vlastností (velikost, chemické, fyzikální a strukturní vlatnosti, therapeutický účinek, toxicita, atd.), z nichž jeden je používán jako učící, trenovací, zatímco druhý (testovací) je používán k ověření vztahů o
dvozených z učícího souboru. Je-li dosaženo shody mezi reálnými a predikovanými výsledky testovacího souboru, je použitý model pravděpodobně dostatečně robusní a správný. Jako potvrzení může posloužit rozšíření testovacího souboru o nové výsledky (látky, vlastnosti), které nebyly v původním souboru zahrnuty.Druhá část testování modelu je spojena s jeho přeurčeností, tj. zjištěním nutného počtu proměnných a jejich funkční závislosti, pro dostatečně správný a robusní popis sledovaného jevu. Pro tuto fázi je vhodné použít statistický test regresní analýzy (viz rov. 3), který zohledňuje jak variabilitu pozorovaného jevu (hodnota koeficientu determinace
R2), tak komplexitu řešeného modelu (počet parametrů p regresní funkce) a počet pozorovaných jevů (N). Platí|
|
(3) |
Statistická významnost regresních parametrů
Ap je testována pomocí t-testu. Platí|
|
(4) |
|
|
(5) |
Vhodnost modelu regresní analýzy je určena hodnotou testu
M podle rovnice 6, dosazením z rovnic 3 a 5. Platí|
|
(6) |
Pro hodnoty M
< 0,3 je použitý model vhodný, zatímco pro M > 0,8 je model přeurčen (zpravidla má větší počet parametrů než je třeba, F>>tΣ, a nebo vykazuje skrytou kolinearitu nezávisle proměnných, tΣ ≈ 0).Řešený příklad predikce lipofility chemických látek (viz tab.1) splňuje výše uvedená kriteria. Zjednodušení rovnice 2 na pouhé dva členy (
l a c ) nevede k lepšímu modelu popisu lipofility, neboť hodnota kriteriua F je pouze 0,03. Postupné přidávání dalších členů rovnice vede ke zvyšování hodnoty kriteria F, tj. zlepšuje model řešící predikci lipofility. V souladu s tímto je zvýšení kriteria F po spojení učícího a testovacího souboru. Závěrem lze říci, že předložený způsob řešení metodou vícenásobné regrese se ukázal jako vhodný a model lipofility vyjádřený jako solvatační interakce jako ověřený.Výše uvedené tvrzení v sobě skrývá jedno z nejpodstatnějších kriterií modelů vedoucích k zobecnění pozorovaných jevů.
Model musí mít fyzikální význam, model není potvrzen vysokou hodnotou statistických kriterií.Přestože se model řešení výše uvedeného pěti-rozměrného prostoru (log
L16, R2H, π2H, α2H, β2H ) jeví formálně správný (vysoká hodnota F a nízká hodnota M), pro obsahové vysvětlení tohoto pravoúhlého, pěti-rozměrného prostoru musíme použít analýzu hlavních komponent (PCA – Principal Component Analysis). Tato analýza ve svém důsledku vede k vytvoření váhy (podílu) jednotlivých komponent (“zdánlivě proměnných”), které popisují sledovaný jev, v našem případě popis chování látek na základě solvatačního modelu (rov. 2). PCA analýza pro 652 látek je ukázána v tab.2.Tabulka 2
PCA analýza 652 látek z hlediska solvatačního chování (rov. 2)
|
Vlastní čísla |
1 |
2 |
3 |
4 |
5 |
|
Hodnota |
2,188 |
1,101 |
0,818 |
0,734 |
0,160 |
|
Podíl komponenty na variabilitě [%] |
43,8 |
22,0 |
16,4 |
14,7 |
3,2 |
|
Celková vysvětlená variabilita [%] |
43,8 |
65,8 |
82,1 |
96,8 |
100 |
|
Vlastní vektory |
1 |
2 |
3 |
4 |
5 |
|
l |
-0,045 |
0,815 |
0,481 |
0,320 |
0,002 |
|
r |
0,491 |
0,416 |
-0,443 |
-0,321 |
-0,535 |
|
s |
0,625 |
0,098 |
-0,203 |
0,139 |
0,734 |
|
a |
0,385 |
-0,163 |
0,699 |
-0,581 |
-0,003 |
|
b |
0,467 |
-0,355 |
0,208 |
0,662 |
-0,418 |
Provedená analýza umožňuje interpretaci modelu z hlediska fyzikálně chemického významu, tj. poznání kausálního vztahu příčiny a následku, v našem případě z chemického hlediska. Diskutovaný příklad ukazuje:
Výše uvedené příklady ukazují nedělitelnost analytického postupu s vytvořením obecně platného závěru, který ve formě kausálního vztahu dovoluje predikci budoucích jevů. Klíčovým bodem při aplikaci metod více-rozměrné statistiky je nutnost fyzikálně chemické interpretace zís
kaných numerických charakteristik řešených modelů.