Kontingenční tabulky (pivot tables) představují jeden z nejmocnějších
nástrojů na účinnou analýzu a třídění velkého množství dat.
Slouží k vytváření přehledů z rozsáhlých databází, přičemž jednotlivé
hodnoty shrnují do vybraných kategorií ve sloupcích a řádcích.
Pro cvičení použijeme opět soubor rhin.xls z balíku dat xl2.zip
1. Otevřeme soubor rhin.xls
2. Prohlédneme si data
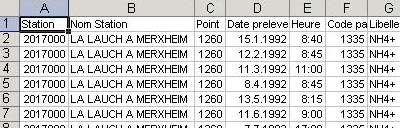
Soubor obsahuje údaje o naměřených průtocích a koncentracích vybraných
ukazatelů kvality vody na kontrolním profilu Merxheim řeky Lauch v v povodí
Rýna v severovýchodní Francii.
Data jsou ponechána v surovém formátu, tak, jak je získáme od poskytovatele. Kvůli úspornosti se při záznamech velkých objemů dat používá sekvenční řazení záznamů v řádcích, přičemž jednotlivé ukazatele nejsou uváděny v oddělených sloupcích jako např. v souboru zavislost.xls, ale tak, aby každý konkrétní výsledek pro každý parametr byl na samostatném řádku. Stejný princip je používán např. i pro data klimatická.
3. Stanovíme cíl analýzy
Z nepřehledné databáze potřebujeme rychle vytvořit přehled časového
vývoje průměrných ročních hodnot pěti parametrů:
- průtok (Q ISNT.)
- BSK5 (DBO5)
- CHSK (COD)
- NH4+ (NH4+)
- celkový fosfor (P total)
Pro přeuspořádání dat a výpočet použijeme nástroj Kontingenční tabulka.
4. Spuštění kontingenční tabulky
Postavíme kurzor do oblasti dat a z menu Data zvolíme položku Kontingenční
tabulka a graf...:

Vyvoláním této položky se dostaneme do průvodce, který nám ve třech krocích pomůže sestavit kontingeční tabulku.
První dvě okna průvodce můžeme nechat bez povšimnutí a potvrdit volby, které se nám automaticky nabízejí tlačítkem Další.
Třetí okno obsahuje důležitý rozcestník k nastavení parametrů kontingenční
tabulky:
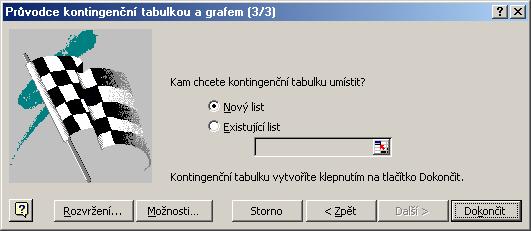
Tlačítko Rovržení použijeme k definici vlastního uspořádání tabulky.
Tlačítko Možnosti pro nastavení některých voleb - jako např. automatických
součtů řádků a sloupců apod.
Důležitá je volba kam chceme kontingenční tabulku umístit - obecně
je vždy přehlednější, umístíme-li ji na samostatný nový list.
5. Rozvržení kontingenční tabulky
Přetažením tlačítek polí do záhlaví sloupců a řádek a vlastní datové
oblasti vytvoříme strukturu tabulky.
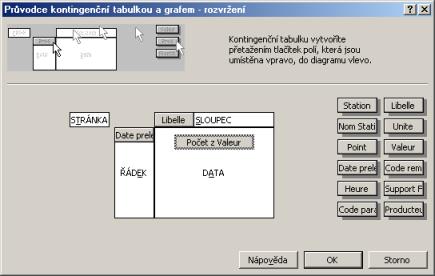
Do záhlaví řádků přetáhneme pole pro datum - (Date prelevement)
Do záhlaví sloupců přetáhneme pole s jednotlivými typy ukazatelů (Libelle)
Do hlavního datového pole přetáhneme vlastní naměřené hodnoty (Valeur)
Při přetažení pole do oblasti hodnot Excel automaticky nabídne operaci,
která bude upravovat data, sdružená podle záhlaví sloupců a řádků.
Protože chceme vypočítat průměrné roční hodnoty, změníme funkci Počet
hodnot na Průměr tím, že poklepeme na tlačítko Počet z Valeur a
označíme funkci Průměr.
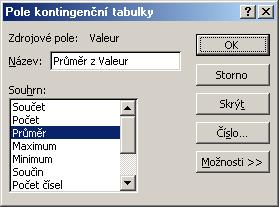
Zároveň v tomto kroku můžeme nastavit zobrazení výsledné průměrné hodnoty tím, že klepneme na tlačítko Číslo a z menu Formát buněk vybereme typ číslo se dvěma desetinými místy.
Dialog potvrdíme OK a vrátíme se do hlavního rozvržení kontingenční
tabulky, kterou máme tímto hotovou.
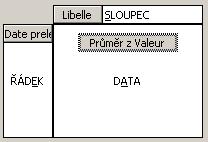
Potvrdíme nastavení rozvržení i třetího kroku průvodce a vytvoříme kontingenční tabulku.
5. Vytvoření souhrnu dat
Vytvořená kontingenční tabulka nyní obsahuje na každém řádku jednu
hodnotu pro každý ukazatel, uvedený v záhlaví sloupce.
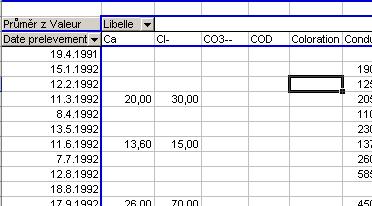
Abychom ji zpřehlednili, sdružíme data tak, aby místo konkrétních dat
odběrů reprezentovala celé roky.
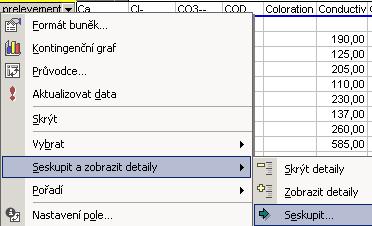
Pravým tlačítkem myši proto klepneme na záhlaví sloupce Date prelevement
a zvolíme nabídku Seskupit a zobrazit detaily, potom volbu Seskupit.
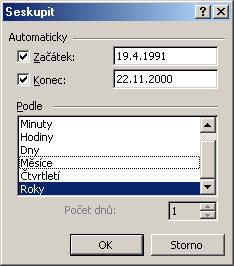
V následném dialogu zvolíme položku roky, čímž data seskupíme podle
let.
6. Výběr parametrů
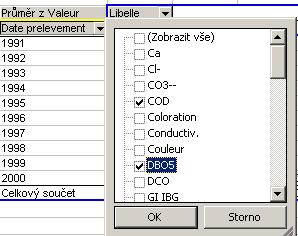
Ve sloupcích se nám stále nachází více parametrů, než potřebujeme.
Abychom vybrali pouze ty, o které máme zájem, klepneme myší na roletové
menu u záhlaví sloupců Libelle a vybereme pouze paramtery, které chceme
mít zobrazené:
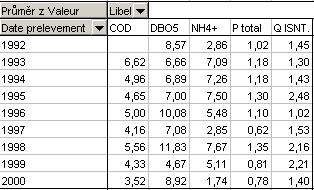
5. HOTOVO!
Prohlédneme si výsledek - z více než 2400 záznamů v téměř 30 parametrech
máme vytvořenu přehlednou tabulku průměrných ročních hodnot několika vybraných
ukazatelů: